




|
Navigation
Search
|
How to build RAG at scale
Tuesday December 30, 2025. 10:00 AM , from InfoWorld
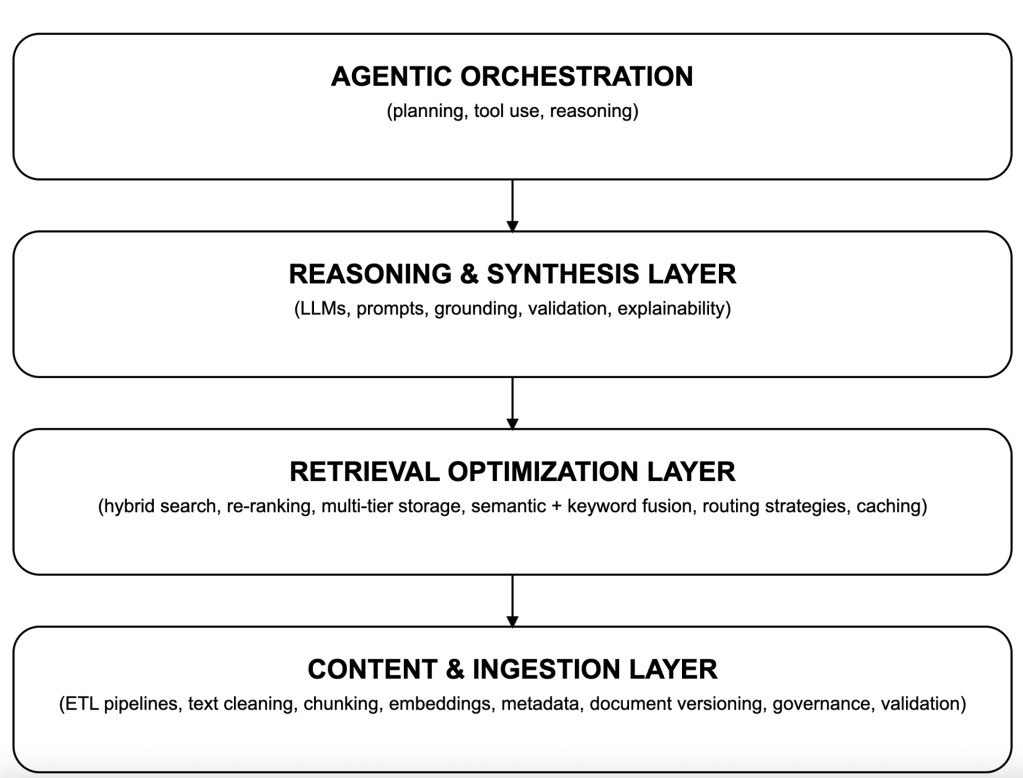
This gap has nothing to do with model quality. It is a systems architecture problem. RAG breaks at scale because organizations treat it like a feature of large language models (LLMs) rather than a platform discipline. The real challenges emerge not in prompting or model selection, but in ingestion, retrieval optimization, metadata management, versioning, indexing, evaluation, and long-term governance. Knowledge is messy, constantly changing, and often contradictory. Without architectural rigor, RAG becomes brittle, inconsistent, and expensive. RAG at scale demands treating knowledge as a living system Prototype RAG pipelines are deceptively simple: embed documents, store them in a vector database, retrieve top-k results, and pass them to an LLM. This works until the first moment the system encounters real enterprise behavior: new versions of policies, stale documents that remain indexed for months, conflicting data in multiple repositories, and knowledge scattered across wikis, PDFs, spreadsheets, APIs, ticketing systems, and Slack threads. When organizations scale RAG, ingestion becomes the foundation. Documents must be normalized, cleaned, and chunked with consistent heuristics. They must be version-controlled and assigned metadata that reflects their source, freshness, purpose, and authority. Failure at this layer is the root cause of most hallucinations. Models generate confidently incorrect answers because the retrieval layer returns ambiguous or outdated knowledge. Knowledge, unlike code, does not naturally converge. It drifts, forks, and accumulates inconsistencies. RAG makes this drift visible and forces enterprises to modernize knowledge architecture in a way they’ve ignored for decades. Retrieval optimization is where RAG succeeds or fails Most organizations assume that once documents are embedded, retrieval “just works.” Retrieval quality determines RAG quality far more than the LLM does. As vector stores scale to millions of embeddings, similarity search becomes noisy, imprecise, and slow. Many retrieved chunks are thematically similar but semantically irrelevant. The solution is not more embeddings; it is a better retrieval strategy. Large-scale RAG requires hybrid search that blends semantic vectors with keyword search, BM25, metadata filtering, graph traversal, and domain-specific rules. Enterprises also need multi-tier architectures that use caches for common queries, mid-tier vector search for semantic grounding, and cold storage or legacy data sets for long-tail knowledge. The retrieval layer must behave more like a search engine than a vector lookup. It should choose retrieval methods dynamically, based on the nature of the question, the user’s role, the sensitivity of the data, and the context required for correctness. This is where enterprises often underestimate the complexity. Retrieval becomes its own engineering sub-discipline, on par with devops and data engineering. Reasoning, grounding, and validation protect answers from drift Even perfect retrieval does not guarantee a correct answer. LLMs may ignore context, blend retrieved content with prior knowledge, interpolate missing details, or generate fluent but incorrect interpretations of policy text. Production RAG requires explicit grounding instructions, standardized prompt templates, and validation layers that inspect generated answers before returning them to users. Prompts must be version-controlled and tested like software. Answers must include citations with explicit traceability. In compliance-heavy domains, many organizations route answers through a secondary LLM or rule-based engine that verifies factual grounding, detects hallucination patterns, and enforces safety policies. Without a structure for grounding and validation, retrieval is only optional input, not a constraint on model behavior. A blueprint for enterprise-scale RAG Enterprises that succeed with RAG rely on a layered architecture. The system works not because any single layer is perfect, but because each layer isolates complexity, makes change manageable, and keeps the system observable. Below is the reference architecture that has emerged through large-scale deployments across fintech, SaaS, telecom, healthcare, and global retail. It illustrates how ingestion, retrieval, reasoning, and agentic automation fit into a coherent platform. To understand how these concerns fit together, it helps to visualize RAG not as a pipeline but as a vertically integrated stack, one that moves from raw knowledge to agentic decision-making: Foundry This layered model is more than an architectural diagram: it represents a set of responsibilities. Each layer must be observable, governed, and optimized independently. When ingestion improves, retrieval quality improves. When retrieval matures, reasoning becomes more reliable. When reasoning stabilizes, agentic orchestration becomes safe enough to trust with automation. The mistake most enterprises make is collapsing these layers into a single pipeline. That decision works for demos but fails under real-world demands. Agentic RAG is the next step toward adaptive AI systems Once the foundational layers are stable, organizations can introduce agentic capabilities. Agents can reformulate queries, request additional context, validate retrieved content against known constraints, escalate when confidence is low, or call APIs to augment missing information. Instead of retrieving once, they iterate through the steps: sense, retrieve, reason, act, and verify. This is what differentiates RAG demos from AI-native systems. Static retrieval struggles with ambiguity or incomplete information. Agentic RAG systems overcome those limitations because they adapt dynamically. The shift to agents does not eliminate the need for architecture, it strengthens it. Agents rely on retrieval quality, grounding, and validation. Without these, they amplify errors rather than correct them. Where RAG fails in the enterprise Despite strong early enthusiasm, most enterprises confront the same problems. Retrieval latency climbs as indexes grow. Embeddings drift out of sync with source documents. Different teams use different chunking strategies, producing wildly inconsistent results. Storage and LLM token costs balloon. Policies and regulations change, but documents are not re-ingested promptly. And because most organizations lack retrieval observability, failures are hard to diagnose, leading teams to mistrust the system. These failures all trace back to the absence of a platform mindset. RAG is not something each team implements on its own. It is a shared capability that demands consistency, governance, and clear ownership. A case study in scalable RAG architecture A global financial services company attempted to use RAG to support its customer-dispute resolution process. The initial system struggled: retrieval returned outdated versions of policies, latency spiked during peak hours, and agents in the call center received inconsistent answers from the model. Compliance teams raised concerns when the model’s explanations diverged from the authoritative documentation. The organization re-architected the system using a layered model. They implemented hybrid retrieval strategies that blended semantic and keyword search, introduced strict versioning and metadata policies, standardized chunking across teams, and deployed retrieval observability dashboards that exposed cases where documents contradicted each other. They also added an agent that automatically rewrote unclear user queries and requested additional context when initial retrieval was insufficient. The results were dramatic. Retrieval precision tripled, hallucination rates dropped sharply, and dispute resolution teams reported significantly higher trust in the system. What changed was not the model but the architecture surrounding it. Retrieval is the key RAG is often discussed as a clever technique for grounding LLMs, but in practice it becomes a large-scale architecture project that forces organizations to confront decades of knowledge debt. Retrieval, not generation, is the core constraint. Chunking, metadata, and versioning matter as much as embeddings and prompts. Agentic orchestration is not a futuristic add-on, but the key to handling ambiguous, multi-step queries. And without governance and observability, enterprises cannot trust RAG systems in mission-critical workflows. Enterprises that treat RAG as a durable platform rather than a prototype will build AI systems that scale with their knowledge, evolve with their business, and provide transparency, reliability, and measurable value. Those who treat RAG as a tool will continue to ship demos, not products. — New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
https://www.infoworld.com/article/4108159/how-to-build-rag-at-scale.html
Related News |

25 sources
Current Date
Dec, Tue 30 - 13:07 CET
|